
{kind=link}
深入云账单,面向两个关键因素进行云成本优化
云账单的发展历程
云账单随着云计算的复杂进程,也经历过一系列的发展。我们以 AWS 为例来看看过去的历史:
2008:发票
这是云账单的起源,通过发票可以看见月度账单和服务账单,但它却少细粒度的服务数据展示,所以常常会被财务团队问到:“这张发票的数据有错吗?钱花在哪里了?”。
2012:成本分配报告(CAR)
为了回答前面的问题,展示成本是哪些团队账号花的、花在哪个服务上,CAR 设计了账户的单独数据行,可以进行支出分配了,推动费用展示和费用分摊。但它的频率还是月度报告,无法分析支出的出现时间和峰值时间。
2013:详细账单报告(DBR)
最大的特点是引入了时间序列。此时可以查询某一项服务在特定月份的支出了,并且可以看到支出的具体时间。
2014:附有资源项和标注的详细账单报告(DBR-RT)
在前面 DBR 的基础上,展示了各时间段使用的资源明细,我们可以了解到特定时间段、特定资源ID的具体支出了,实现了支出的精确定位。此时,数据量极速增长,账单分析变得十分复杂。
2017:成本和使用报告(CUR)
账单文件以 JSON 格式替代,便于程序读取。信息量承载更强、账单可以通过自主的数据程序进行读取和分析。我们的工作变得更工程化了,这也是 FinOps 的进化。
从以上历史可以看出,云账单数据一步一步变得复杂,因为承载的信息量愈加庞大、对账单的时效性要求越来越高。现在,仅 AWS 一家云厂商就有超过 20万 个产品库存单位(SKU),部分产品甚至按秒计费。这些账单每时每刻刷新,与实例运行时长、实例大小等存在复杂的联系。
深入云账单的数据结构
接下来我们深入了解云账单的数据格式,以便了解云成本的来龙去脉和计算逻辑。以 AWS 实际云账单为例,下面展示一下详细账单生成过程和详细:
创建云账单的方法
创建云账单并不难,每个云厂商提供了相应的账单生成方法,页面上操作即可实现。
以 AWS 为例,详细操作可以看“本文参考”的链接部分,大致的过程是选择一个 S3 数据桶进行账单文件存储 -> 配置账单所需要的内容和生成频率即可,非常方便,配置页面如下图:
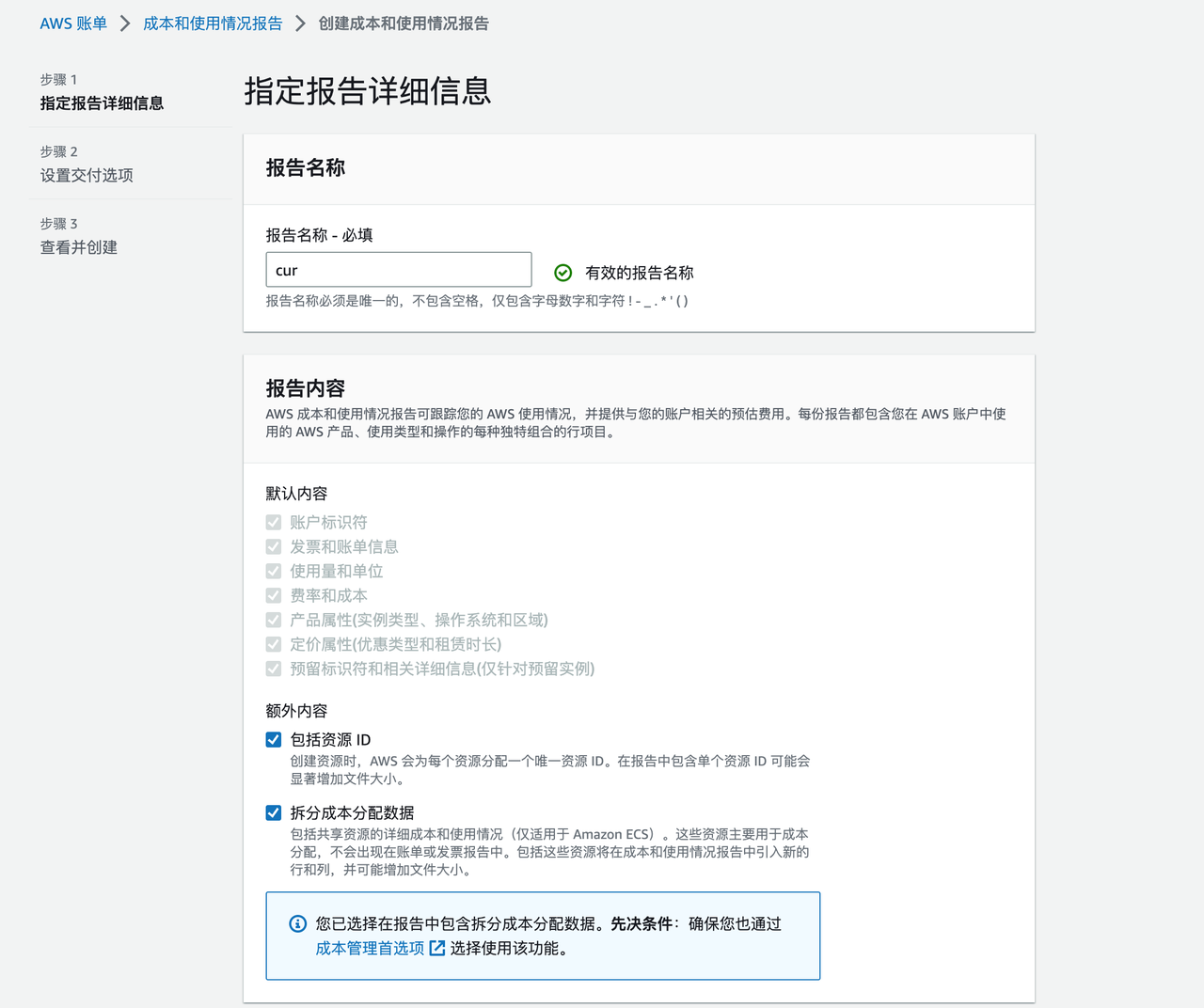
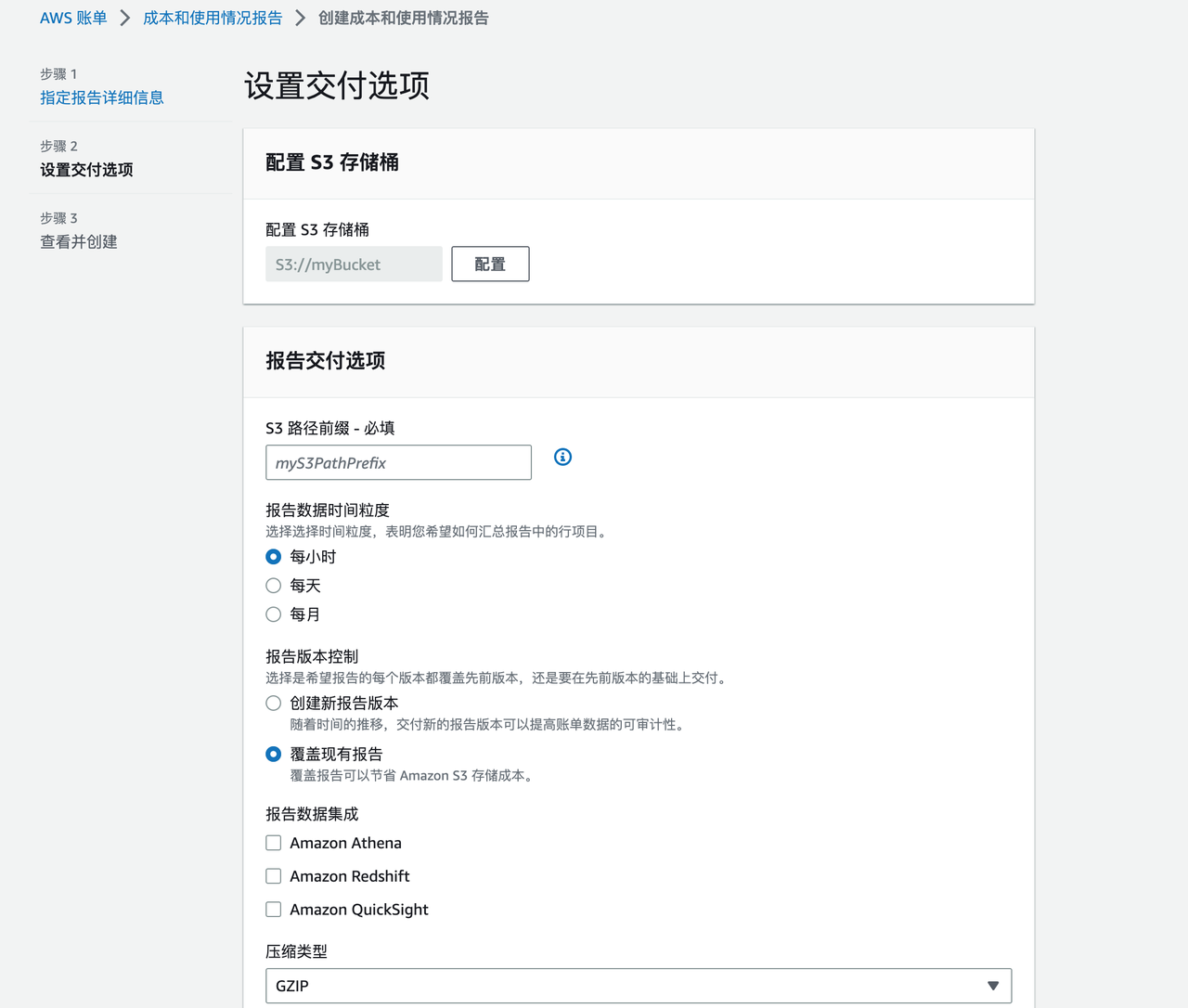
核心关注上面的两个内容:
- 报告内容:默认内容(使用量和单位、费率和成本、定价属性-优惠类型和租赁时长)和额外内容(资源 ID、拆分成本分配数据);
- 交付选项—时间粒度:报告中的行项目可选择按“每月”、“每天”或“每小时”聚合;
可见报告粗粒度是可以自主选择的。内容粒度越细、时间粒度越小,则报告越大(几百MB一个报告文件并不难),分析难度越大、但可分析内容越丰富。
查询云账单数据实例
配置了云账单后,云厂商会按照配置的频率自主生成云账单文件。例如 AWS 会将云账单存储在 S3 中:
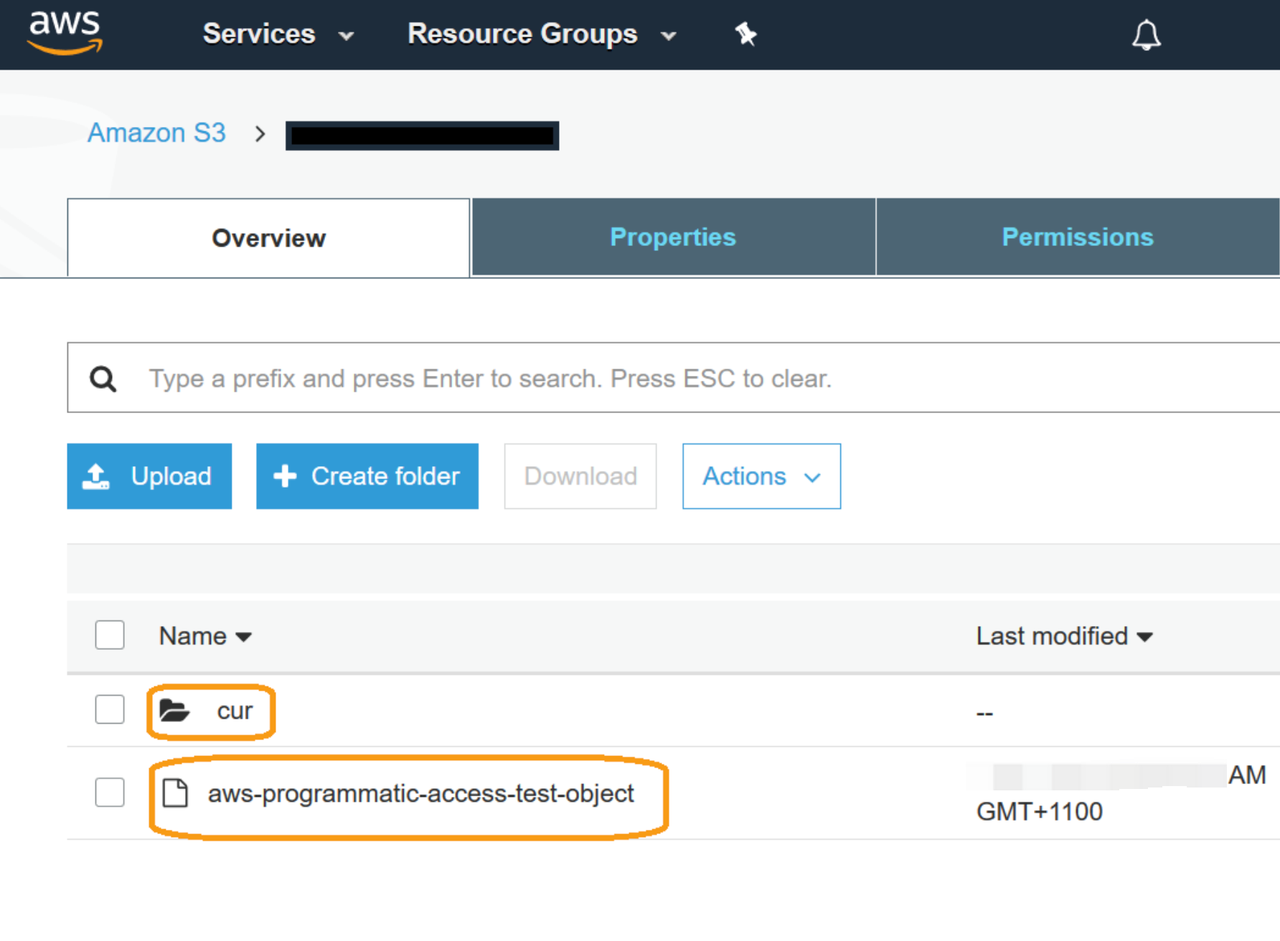
可以看见每一个文件非常大,想根据 Excel 来分析难度极高。所以云厂商一般会提供自己的可视化分析工具(如 AWS Cost Explorer),而 FinOps 工程师可以根据云账单来自主建设可视化能力,以便支持按需观测或多云分析(这部分后续文章会讲到)。
那具体每一个云账单里包含了哪些内容 / 数据字段呢,我这边格式化一下,以更易理解的 DataBase Schema 形式给大家做展示,具体字段如下:
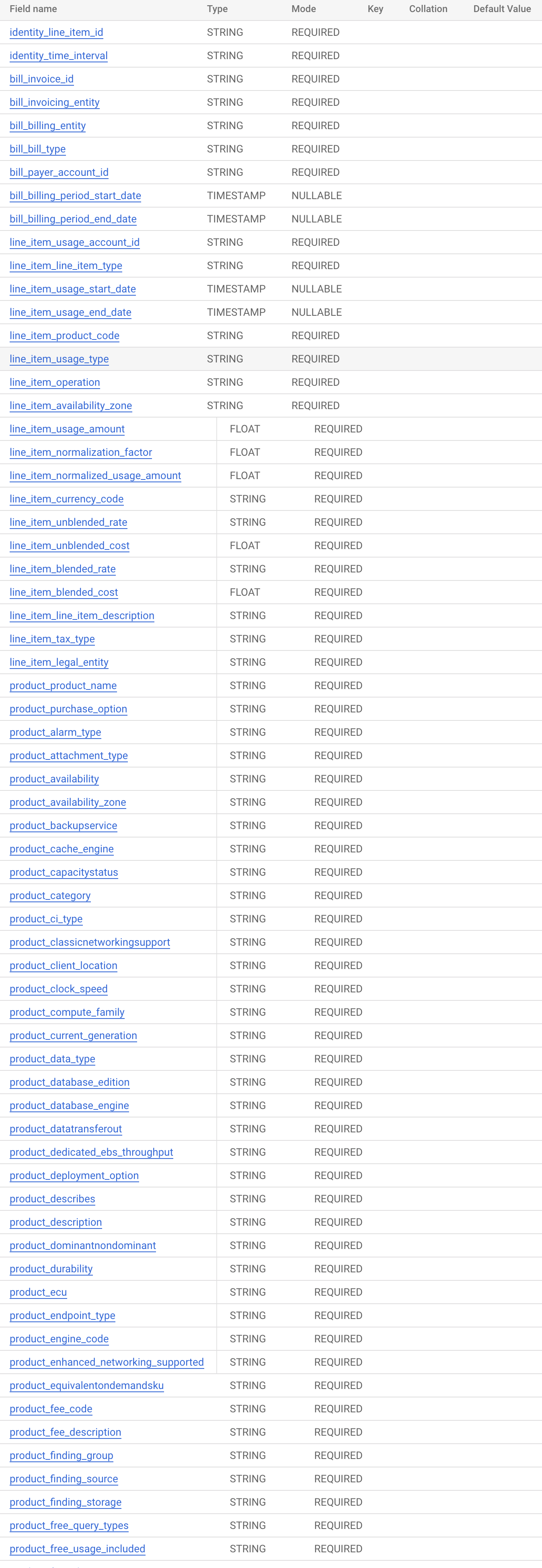
上面只列举了很小一部分,实际字段极多。在这样的数据规模下,已经难以使用电子表格分析了,必须求助于计算机管理系统。但这些细粒度的账单也赋予了 FinOps 强大的分析潜力。
两个关键因素进行云成本优化
再从前面的云账单中抽取关键信息,可以发现一些重要属性:
- 资源的明确 ID、地域、费用(line_item_unblended_cost 等信息);
- 使用资源的时间段(bill_billing_period_start_date~bill_billing_period_end_date,line_item_usage_start_date~line_item_usage_end_date 等信息);
- 应用于账单的费率及用量等信息(line_item_unblended_rate、line_item_usage_amount 等信息);
我们可以看出云账单最重要的核心因素,是:用量和费率。云支出 = 用量 * 费率,其中用量可能是资源的使用时长,费率是每小时(或每秒)使用该资源所支付的金额。这个公式,也是我们接下来分析云成本优化的关键因素所在。
集中式的费率优化
所谓费率,其实有点类似于“单价”,对于云资源,难道单价是可变的?是的。这看起来很不可思议,但实际上大部分云厂商,会为客户提供定制定价计划。而同时,用户可直接使用的还有云厂商的批量折扣服务(AWS SavingsPlans、GCP 的可持续使用折扣)。
同时在资源选择上,并非只有固定规格,我们在用云的时候,可以选择最适合业务场景的规格实例,不同规格费率会有所不同;同时其中还包括对于业务不敏感的程序使用可抢占实例(例如 AWS Spot-Instance 等),折扣甚至能高达 60% 以上;
对于重要业务场景,要求 24h 都有云资源配备,此时还可以通过购买预留实例,为公司各个业务团队共享使用,FinOps 团队需集中关注预留实例的上升情况,保障资源空置率的低值。
分布式的用量优化:时间,还是时间!
在云计算下,我们应该首先了解到:我们在云上购买的不是资源实体,而是一定时间内的资源的使用权,我们本质上购买的是云服务的时间,而非实物。
有了这个认知,我们知道在云上每笔费用都有时间限制,即使固定费率项目也会按月或年收费,我们常见的情况是支付每秒的计算费、存储费、以及查询完成时间而产生的费用(当然,也有时间之外的例外,那就是类似 Serverless 和 数据传输基于用量,但基于用量同样适用于前面的云支出计算模型)。
所以,我们首先需要知道“用量”的可怕之处,那就是:不积跬步,无以至千里,日积月累会导致支出从不起眼而逐步走向无限放大。我们想象一下,云上运行着 50 个计算实例,利用率非常低,看似每天只需要支付 5000 美元,但是时间拉长,一个月这笔浪费就已经超出了 150000 美元!
而云上,现在有很多这样的服务,例如计算实例等,是基于资源用量(含运行时长)进行收费的。所以降低云支出的第一个关键因素,就是:降低资源用量! 具体而言,可以终止闲置资源、调整规格、减少非高峰期的资源数(弹性)、甚至节假日和周末完全停止资源使用。同上一篇文章里讲过的 FinOps 分工来看,FinOps 团队需要为技术团队提供资源可视化入口(不管是自主建设分析工具还是使用云厂商的分析工具),真正控制资源的是应用程序的所有者。这里要特别强调,让工程师或应用程序所有者做出资源调整的决策,过程需要是分布式化的,FinOps 团队只在其中纵观全局,但尽量不做所谓的中心决策,而将资源决策授权出去给各个业务技术团队,这样可以保证决策是最高效的。
为什么需要分布式化保证决策高效,因为决策也需要时间,而时间意味着成本!高效的分布式化以减少用量,是有效降低云成本的第一个重要杠杆因素!
总结
本文了解了云账单的来龙去脉,并深入分析了云账单的数据结构,从而看到在云成本优化过程中,可以重点关注分布式的用量优化(尤其是时间)和集中式的费率优化。看起来并不复杂对吧,从云账单创建和分析开始实践起来吧。
本文参考资料:
- What are AWS Cost and Usage Reports:https://docs.aws.amazon.com/cur/latest/userguide/what-is-cur.html
- Creating Cost and Usage Reports:https://docs.aws.amazon.com/cur/latest/userguide/cur-create.html
- AWS Well-Architect Labs:https://www.wellarchitectedlabs.com/cost/200_labs/200_4_cost_and_usage_analysis/1_verify_cur/
- Configure Cost And Usage Reports:https://wellarchitectedlabs.com/cost/100_labs/100_1_aws_account_setup/3_cur/